About
关于集群信息概述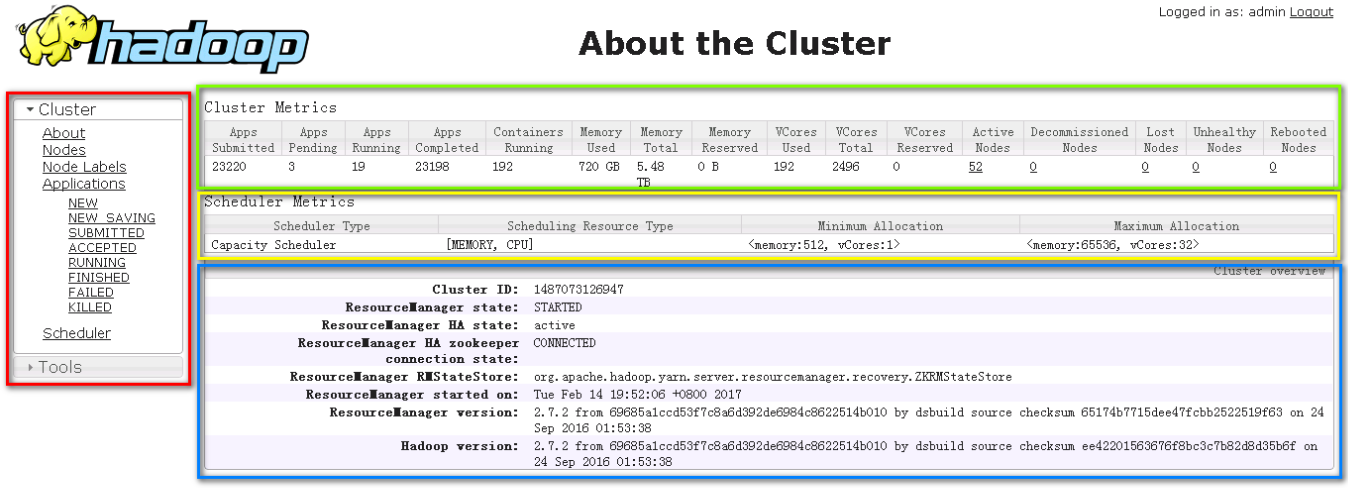 图 1 About the Cluster
图 1 About the Cluster
如上图所示,About介绍了集群总体指标,分为如下4个区域:导航区域(红色)、集群指标区域(绿色)、调度器指标区域(红色)、集群信息区域(蓝色)。下面分别介绍几个区域内容。
导航
整个YARN的UI界面导航。
集群指标
关于集群的所有资源的指标。 图 2 Cluster Metrics
图 2 Cluster Metrics
第一组是关于应用的指标:
- Apps Submitted: 所有提交的应用数量,其数量是Apps Pending+ Apps Running+ Apps Completed的综总和。
- Apps Pending:已经提交但处于挂起状态的应用数量,这些任务正排队等待资源。此处会在集群资源已经用满的情况下发送,起数量越多,代表的集群越繁忙。
- Apps Running:正在运行的应用数量。
- Apps Completed:已经运行完成的应用数量。
第二组涉及集群服务器资源的指标
- Containers Running:正在运行的程序,已经分配的Containter数量。
- Memory Used:已经使用的内存数量,其为集群所有节点的总和。
- Memory Total:集群所有节点的物理内存总和。
- Memory Reserved:集群中保留的内存总和。
- VCores Used:已经分配的VCores数量。
- VCores Total:集群总VCores数量。
- VCores Reserved:保留的VCores数量。
注意:Reserved的原因,是因为container由调度器分配了资源到某个节点上,但是这个节点,已经没有资源了。此时该container会进入reserve状态。
第三组涉及集群各各节点情况的指标
- Active Nodes:活动的节点数量。
- Decommissioned Nodes:已经退服的节点数量。
- Lost Nodes:丢失节点数量。
- Unhealthy Nodes:不健康节点数量。
- Rebooted Nodes:正处于重启状态的数量。
这些重点介绍一下Containter。Containter是执行task的基本单元,其数量决定了集群并行度,所以至关重要。集群中Containter数量是固定的,由几个参数来决定,最主要的是两个参数mapreduce.map.memory.mb和mapreduce.reduce.cpu.vcores,分别决定一个Containter内包含多少内存和多少VCore,例如我的集群设置是4GB和1个VCore。那么根据图 2 2中所示,总内存5.48TB,共可分给5.48TB/4GB=1402个Containter,总VCore数量是2486个,这样看来,内存是不足的,所以集群中仅能分配1402个Containter,很1000多个VCore是没有利用上的。
注意:由于在Application执行时,会分配一个Containter来进行ApplicationMaster工作,这个分配数量是由另一个参数决定的,集群在实际分配时,可能会稍微多于或少少于我们的计算值,但数量差异不大,一般差异在个位数以内。
调度器指标
此段为调度指标,在很多界面都可看到,一版不用修改。 图 3 Scheduler Metrics
图 3 Scheduler Metrics
- 调度器类型:Hadoop调度类型有公平调度器(FairScheduler)和容量调度器(Capacity Scheduler)。图 2 3所示为使用的是容量调度器。
- 调度器资源类型:现在只包含两种,内存和CPU 。
- 调度器最小/最大申请资源:任务向资源调度器申请资源时,每一个container申请的资源范围应比最小资源大,比最大资源小。
集群信息
待完善